Scaling properties have shown time and again to be important to networked communication. Think of the introduction of switches in early telephone exchanges, improvements in time or code division multiplexing in wireless or optical networks, or packet switching on the Internet, all of which impacted the networks’ size, performance, and utility to users – sometimes leading to great advances at other times placing obstacles in the path of growth.
In a similar vein, the technical performance of neural language models (like OpenAI’s ChatGPT) has been shown to have scaling properties. Three distinct factors have been shown to impact performance of neural language models: the number of model parameters N (a rough proxy for a model’s “complexity”), the size of the dataset D, and the amount of compute C used for training. As one or more factors increases, the cross entropy loss of the model scales as a power-law. In layman’s terms, the more parameters, data, and compute the more effective models become at producing information (e.g., accurate classification of data) for the task at hand, i.e., model performance improves.
The growth in the number of parameters in machine learning-based models (including language, but also in other domains) shifted dramatically around 2016-2018. According to AI researchers, it went from historically doubling approximately every 18 months to a doubling time of 4 to 8 months. Similarly, the growth in D (the size of initial training datasets) and C (the amount of computational power used by large scale models) has also increased to a lesser degree. These developments signaled the beginning of the “large scale” era of AI. Scaling seems to be associated with dramatic improvements in cost performance of some commercialized models. But it’s not always clear that more is better, and different combinations of parameters, data, and compute can result in performance improvements. Dis-economies may exist, other resources or characteristics may matter too.
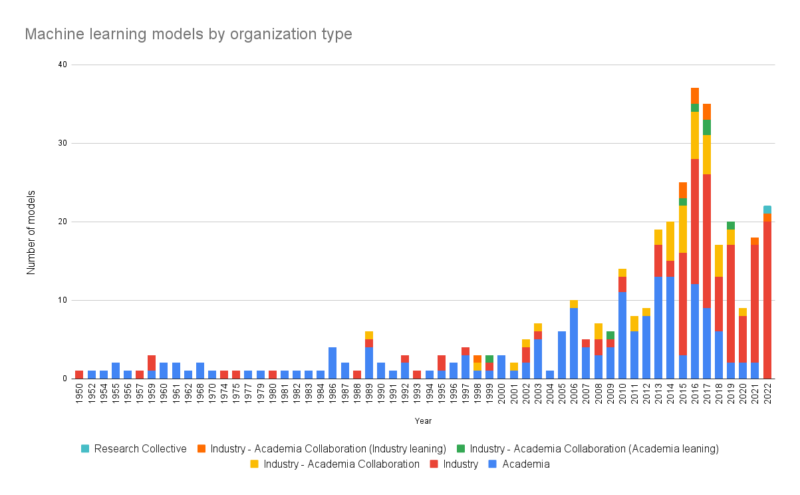
Understanding how parameter, data and compute relate to a model’s technical performance is interesting, these systems don’t exist in a vacuum. Social factors may also affect performance improvements, or other outcomes. The second study above that collected data on over 500 models released since the 1950s also categorized the models by the type of organization(s) that developed them. Looking at this, the role of industry and commercial and market incentives (and particularly efforts of big tech platforms like Google, Facebook, Microsoft, Amazon, Alibaba that co-produce data) appears directly related to growth in parameter, data and compute factors. As the figure indicates, since 2015, industry-academia collaborations and industry developed models have come to dominate the field.
Of course, this is no surprise to those in the field who often move freely back and forth between universities and firms, who are in a position to see the emergence, in the 2000s, of massive, relatively inexpensive, on-demand cloud computing platforms that are now instrumental partners in deploying AI models. But understanding the shift requires a broader, economically grounded understanding of the role of scaling, resources, and how organizational, national and regional policies are shaping the supply and demand of AI-enabled services. Especially now, as almost daily another platform announces yet another commercial Al implementation. Policymakers’ current efforts are focused on preventative measures to prevent undesirable outcomes, and continue to struggle with basic definitions in a dynamic, globally competitive environment.
Market competition between platform and AI provider partnerships to provide “aligned”, “safe”, “responsible” generative models based on risk analysis is already occurring. Policy analysis and makers need to look forward. For instance, how do the properties and rules governing the data these platforms collect impact the initial or fine tuning of providers’ models? How do national and extraterritorial policies concerning compute resources affect model development or performance? To what extent do these policies impact scaling, platforms’ resource constraints and operational costs, and ultimately, firms’ market shares and prices in competing services and products?
Banner photo credit: https://www.wcl.american.edu/impact/initiatives-programs/pijip/news/professor-kathryn-kleimans-research-on-women-in-early-programming-highlighted-at-eniac-75th-anniversary-celebrations/
