In case you missed it (you probably didn’t), the Internet was hit with the Monday blues this week. As operator-focused lists and blogs identified,
At 17:47:05 UTC yesterday (6 November 2017), Level 3 (AS3356) began globally announcing thousands of BGP routes that had been learned from customers and peers and that were intended to stay internal to Level 3. By doing so, internet traffic to large eyeball networks like Comcast and Bell Canada, as well as major content providers like Netflix, was mistakenly sent through Level 3’s misconfigured routers.
In networking lingo, a “route leak” had occurred, and a substantial one at that. Specifically, the Internet was the victim of a Type 6 route leak, where:
An offending AS simply leaks its internal prefixes to one or more of its transit-provider ASes and/or ISP peers. The leaked internal prefixes are often more-specific prefixes subsumed by an already announced, less-specific prefix. The more-specific prefixes were not intended to be routed in External BGP (eBGP). Further, the AS receiving those leaks fails to filter them. Typically, these leaked announcements are due to some transient failures within the AS; they are short-lived and typically withdrawn quickly following the announcements. However, these more-specific prefixes may momentarily cause the routes to be preferred over other aggregate (i.e., less specific) route announcements, thus redirecting traffic from its normal best path.
In this case, the painful result was significant Internet congestion for millions of users in different parts of the world for about 90 minutes.
One of the main culprits apparently fessed up, with CenturyLink/Level 3 quickly issuing a reason for the outage (I pity “that guy”, being a network engineer at the world’s largest ISP ain’t easy).
Can’t we fix this?
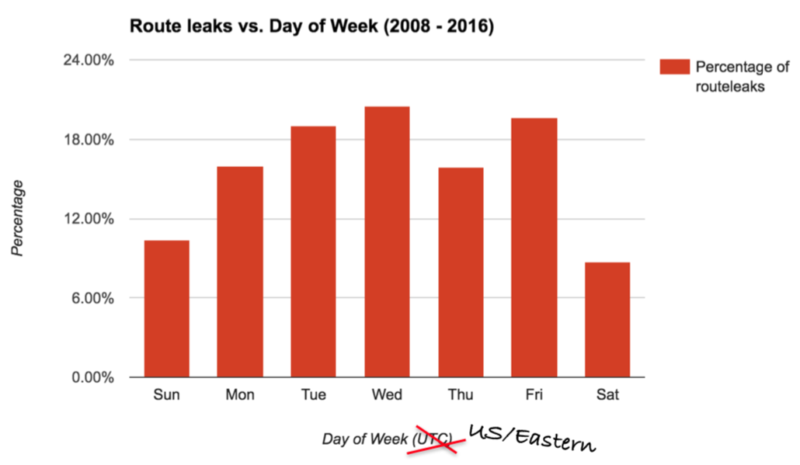
Route leaks are a fact of life on the Internet. According to one ISP’s observations, on any given day of the week, between 10-20% of announcements are actually leaks. Type 6 route leaks can be alleviated in part by technical and/or operational measures. For internal prefixes never meant to be routed on the Internet, one suggestion is to use origin validation to filter leaks, but this requires adoption of RPKI and only deals with two specific types of leak.
From a contractual and operational perspective, Level 3’s customers and others affected are presumably closely scrutinizing their SLAs. Maybe this episode will incentivize Level 3 to take some corrective action(s), like setting a fail-safe maximum announcement limit on their routers to catch potential errors. Perhaps Level 3’s peering partners are similarly considering reconfiguring their routers to not blindly accept thousands of additional routes. Although, the frequency or other characteristics of changes in routing announcements might make this infeasible.
Another potential solution requiring broader collective action is NTT’s peer locking, where NTT prevents leaked announcements from propagating further by filtering on behalf of other ISPs with which it has an agreement. It’s an approach that is mutually beneficial. Much of the routing chaos could have been prevented if peer locking arrangements had been in place between NTT (or other large backbone ISPs peering with Level 3) and any of the impacted ASes (e.g., Comcast had ~20 impacted ASes). NTT has apparently had some success with the approach, having arrangements with many of the world’s largest carriers of Internet traffic. In every case where they deployed peer locking, the number of route leaks has decreased by an order of magnitude. Moreover, the approach is apparently being replicated by other large carriers.
Regardless of the solution(s) implemented, the complexity of the problem space highlights the ongoing importance of understanding routing data governance and operator incentives to engage in filtering. We also need to be able to empirically assess over time whether or not specific approaches relate to observed variance in different types of route leaks.

https://tools.ietf.org/html/draft-ietf-idr-bgp-open-policy-01
Solves the case of “sticky fingers”